Check out Paul Bedaride's very handy darcs cheet sheat. It gives you basically everything you need to know about darcs on a single sheet of A4 paper. I'm sure Paul would appreciate any appropriate criticism you may have.
2007-12-23
2007-12-18
mail?
So we have in Haskell quite a few consumer applications
When's the mail client coming? I'm asking this in the random speculative sense, not in the "gimme a Haskell mail client now" sense. What would a Haskell mail client look like? I'm guessing that plugins will play a nice role, extensibility and all. Being able to handle really large mailboxes (a big "archive" folder) would be nice. Perhaps Sup would be good inspiration. Come to think of it, maybe the client should be implemented in Cat, just for the name...
When's the mail client coming? I'm asking this in the random speculative sense, not in the "gimme a Haskell mail client now" sense. What would a Haskell mail client look like? I'm guessing that plugins will play a nice role, extensibility and all. Being able to handle really large mailboxes (a big "archive" folder) would be nice. Perhaps Sup would be good inspiration. Come to think of it, maybe the client should be implemented in Cat, just for the name...
2007-12-06
Setup.(l)hs
One minor annoyance when using Cabal to install stuff is that not every project agrees on whether the Setup script should be an .hs or an .lhs file. The consequence is that when doing a bunch of installations, I'll hit the up arrow to re-run, say, runhaskell Setup.lhs configure and it will complain that the file is not found, because this project uses .hs and the project just before uses .lhs.
What I'm wondering, though is if it would be a good idea for projects to distribute both files? We could even use something like this to have the same file regardless of extension:
I guess that once cabal-install comes out, none of this would really matter since all that building-of-dependencies stuff would be taken care of automatically.
What I'm wondering, though is if it would be a good idea for projects to distribute both files? We could even use something like this to have the same file regardless of extension:
#!/usr/bin/env runhaskell
{-
> import Distribution.Simple
> main = defaultMain
-}
import Distribution.Simple
main = defaultMain
I guess that once cabal-install comes out, none of this would really matter since all that building-of-dependencies stuff would be taken care of automatically.
David Roundy is the new darcs unstable maintainer
Just wanted to announce that I am ending my stint as unstable branch maintainer and transferring the responsibility back to David. This will help me to keep up with my new life and job, and help David to usher in the new darcs-2.0.
I hope I'll be able to continue participating, maybe submitting a patch or two when things settle down over here. In the meantime, it's been fun and I've learned a lot.
So thanks for everything and good luck with 2.0!
I hope I'll be able to continue participating, maybe submitting a patch or two when things settle down over here. In the meantime, it's been fun and I've learned a lot.
So thanks for everything and good luck with 2.0!
2007-11-06
PhD viva (defense)
I'll be presenting my thesis next Wednesday. You are cordially invited to attend the defence and to join us for drinks afterwards.
Surface realisation: ambiguity and determinism
Eric Kow
14 November 2007
Amphi C, LORIA
Nancy, France
Surface realisation is a subtask of natural language generation. It may be viewed as the inverse of parsing, that is, given a grammar and a representation of meaning, the surface realiser produces a natural language string that is associated by the grammar to the input meaning. This thesis presents three extensions to GenI, a realisation algorithm for Feature-Based Tree Adjoining Grammar (FB-LTAG).
The first extension improves the efficiency of the realiser with respect to lexical ambiguity. It is an adaptation from parsing of the "electrostatic tagging" optimisation, in which lexical items are associated with a set of polarities, and combinations of those items with non-neutral polarities are filtered out.
The second extension deals with the number of outputs returned by the realiser. Normally, the GenI algorithm returns all of the sentences associated with the input logical form. Whilst these inputs can be seen as having the same core meaning, they often convey subtle distinctions in emphasis or style. It is important for generation systems to be able to control these extra factors. Here, we show how the input specification can be augmented with annotations that provide for the fine-grained control that is required. The extension builds off the fact that the FB-LTAG grammar used by the generator was constructed from a "metagrammar", explicitly putting to use the linguistic generalisations that are encoded within.
The final extension provides a means for the realiser to act as a metagrammar-debugging environment. Mistakes in the metagrammar can have widespread consequences for the grammar. Since the realiser can output all strings associated with a semantic input, it can be used to find out what these mistakes are, and crucially, their precise location in the metagrammar.
Surface realisation: ambiguity and determinism
Eric Kow
14 November 2007
Amphi C, LORIA
Nancy, France
Surface realisation is a subtask of natural language generation. It may be viewed as the inverse of parsing, that is, given a grammar and a representation of meaning, the surface realiser produces a natural language string that is associated by the grammar to the input meaning. This thesis presents three extensions to GenI, a realisation algorithm for Feature-Based Tree Adjoining Grammar (FB-LTAG).
The first extension improves the efficiency of the realiser with respect to lexical ambiguity. It is an adaptation from parsing of the "electrostatic tagging" optimisation, in which lexical items are associated with a set of polarities, and combinations of those items with non-neutral polarities are filtered out.
The second extension deals with the number of outputs returned by the realiser. Normally, the GenI algorithm returns all of the sentences associated with the input logical form. Whilst these inputs can be seen as having the same core meaning, they often convey subtle distinctions in emphasis or style. It is important for generation systems to be able to control these extra factors. Here, we show how the input specification can be augmented with annotations that provide for the fine-grained control that is required. The extension builds off the fact that the FB-LTAG grammar used by the generator was constructed from a "metagrammar", explicitly putting to use the linguistic generalisations that are encoded within.
The final extension provides a means for the realiser to act as a metagrammar-debugging environment. Mistakes in the metagrammar can have widespread consequences for the grammar. Since the realiser can output all strings associated with a semantic input, it can be used to find out what these mistakes are, and crucially, their precise location in the metagrammar.
2007-10-29
darcs conflicts faq
Pekka Pessi and I have put together an FAQ on the darcs conflict problem. It has three major sections:
- Everyday conflicts: what conflicts are and how you should deal with them in the general case.
- The big conflicts bug: what it is, how you can avoid it, and what to do if you have run into trouble.
- Darcs 2.0: from a user perspective, how it will change from darcs 1.x (not very much), and what resolving conflicts might look like (rollback will play a bigger role). David has been making some great progress. Nevertheless, our best estimates are that we will be ready for alpha testing only in Feb 2008, and release by the second quarter of that year.
2007-10-24
getting things done with mutt 3 (action counter)
Here's a short tip for putting a reminder on your desktop wallpaper of how many next-action and waiting-for messages you have. The result looks like this:
The approach is to combine a small shell script with the wonderful GeekTool program for MacOS X (similar programs exist for Linux, I'm sure). GeekTool lets you display arbitrary text, say console text on your Desktop. One of my GeekTool windows is set to run the script and display its results with a big red font.
The shell script is pretty dumb; it just counts the number of files in my Maildir directory. I guess if you're using the mbox format, you'll have to find some other way to count messages. Count the number of instances of '^From: ', maybe?
I'm not expecting this to have a huge impact on my productivity, but maybe this will be that extra little bit that counts.
Edit 2007-10-25Fixed counting to account for empty boxes. Zero. We like that number.
ACTION: 4
WAITING: 1
The approach is to combine a small shell script with the wonderful GeekTool program for MacOS X (similar programs exist for Linux, I'm sure). GeekTool lets you display arbitrary text, say console text on your Desktop. One of my GeekTool windows is set to run the script and display its results with a big red font.
The shell script is pretty dumb; it just counts the number of files in my Maildir directory. I guess if you're using the mbox format, you'll have to find some other way to count messages. Count the number of instances of '^From: ', maybe?
#!/bin/sh
# $2 is just for padding
function count_messages (){
echo -n "$1:$2"; ls -1 ${HOME}/Mail/current/$1/cur | wc -l
}
count_messages ACTION " "
count_messages WAITING
I'm not expecting this to have a huge impact on my productivity, but maybe this will be that extra little bit that counts.
Edit 2007-10-25Fixed counting to account for empty boxes. Zero. We like that number.
2007-09-21
kowthese 1.0
I thought I might announce version 1.0 of my PhD thesis: Surface realisation: ambiguity and determinism
This is the version that went out to the committee, so it is not definitive (you may prefer to wait for version 1.1 in December). It's also not very Haskell-related, aside from the fact that the software inside is written in Haskell. If you are interested, the overall topic area is computational linguistics (natural language processing), specifically, natural language generation.
Oh, and the darcs repository for the thesis (LaTeX sources):
This is the version that went out to the committee, so it is not definitive (you may prefer to wait for version 1.1 in December). It's also not very Haskell-related, aside from the fact that the software inside is written in Haskell. If you are interested, the overall topic area is computational linguistics (natural language processing), specifically, natural language generation.
Oh, and the darcs repository for the thesis (LaTeX sources):
darcs get http://www.loria.fr/~kow/kowtheseThe viva/defense to be held on 2007-11-14.
2007-08-25
getting things done with mutt 2 (auto-review)
Last year, I posted some ideas for applying GTD to mutt. As you may have heard, GTD is a simple methodology to help people stay on top of things. The basic idea in my post was to use an on-board X-Label editor to associate each message with a 'next action' or a 'waiting for' tag, and to store them in the respective mailboxes ACTION and WAITING. This was accompanied by a small colour configuration to highlight the X-Label field of each message, thus making it clear at all times what the next action was.
After one year of use, I can report that I am 95% happy with the system. It is simple and effective... however, not entirely eric-proof. In this post, I propose a small addition to tighten up the system and make it more resistant to my foolishness. The problem is that GTD is a heavily review-oriented system. Once you move tasks out of your head and onto some external device (e.g. a pad of paper), you must also consult that device from time to time or risk forgetting to do them. For example, one thing that can easily happen to me is that I will move messages into ACTION and WAITING and simply forget they are there.
This is where the idea of automated review comes in. What I propose a simple method for reminding yourself that you have next actions to perform, or things that you are waiting on. It consists of a shell script and a crontab entry. First the script (I call it gtd-review):
And now the crontab:
Anyway, I hope others find this to be useful.
After one year of use, I can report that I am 95% happy with the system. It is simple and effective... however, not entirely eric-proof. In this post, I propose a small addition to tighten up the system and make it more resistant to my foolishness. The problem is that GTD is a heavily review-oriented system. Once you move tasks out of your head and onto some external device (e.g. a pad of paper), you must also consult that device from time to time or risk forgetting to do them. For example, one thing that can easily happen to me is that I will move messages into ACTION and WAITING and simply forget they are there.
This is where the idea of automated review comes in. What I propose a simple method for reminding yourself that you have next actions to perform, or things that you are waiting on. It consists of a shell script and a crontab entry. First the script (I call it gtd-review):
#!/bin/sh
# note: I am using the maildir format; if you are using mbox,
# you should just replace the 'find $1 | xargs $1' with 'cat $1'
function summarise () {
find $1 | xargs cat |\
sed -n -e '/^X-Label/G' -e '/^X-Label/p'\
-e '/^From/p' -e '/^Subject/p' -e '/^Date/p' |\
sed -e 's/From: //' -e 's/Date: //' -e 's/Subject: //'
}
echo '======================================================================'
echo 'ACTIONS'
echo '======================================================================'
echo
summarise ${HOME}/Mail/ACTION
echo '======================================================================'
echo 'WAITING'
echo '======================================================================'
echo
summarise ${HOME}/Mail/WAITING
And now the crontab:
@daily gtd-review 2>&1 /dev/null | mail -s "GTD review `date +%Y-%m-%d`" me@myaddress.comI'm sure you could improve on this. For example, I would rather the dates were presented in yyyy-mm-dd format and accompanied with a friendlier description like "3 weeks ago"... but working on that would probably count as fidgeting.
Anyway, I hope others find this to be useful.
2007-08-16
a history of monad tutorials
Here's a historical overview of monad tutorials since Phil Wadler's original observation that monads can be implemented in Haskell and become extremely useful.
When I wrote this, I originally wanted to do a real history, with an analysis of how people have tried to teach monads over the years, but I guess this is about all I have time for. Dates, authors and blurbs. Corrections/additions always welcome! As you can tell, I have not read them all.
Edit 2007-08-17: I have updated and moved this timeline to Haskellwiki. This might be useful when some future Haskell archeologist tries to figure out the precise "ah-ha!" moment when every single programmer in the world 'got' monads.
When I wrote this, I originally wanted to do a real history, with an analysis of how people have tried to teach monads over the years, but I guess this is about all I have time for. Dates, authors and blurbs. Corrections/additions always welcome! As you can tell, I have not read them all.
Edit 2007-08-17: I have updated and moved this timeline to Haskellwiki. This might be useful when some future Haskell archeologist tries to figure out the precise "ah-ha!" moment when every single programmer in the world 'got' monads.
2007-08-14
Haskell 是一门函数式编程语言。
Looks like some wikibookian(s) have embarked upon a Chinese translation of the Haskell wikibook. Good luck to them! Chinese speakers might be interested in jumping on board. As for non Chinese speakers, the sentence above is "Haskell is a functional programming language."
2007-07-19
monomorphism redux
There may be errors in this, of course!
Following the previous example, you might be tempted to try storing a value for that radius. Let's see what happens:
Whoops! You've just run into a programming concept known as types. Types are a feature of many programming languages which are designed to catch some of your programming errors early on so that you find out about them before it's too late. We'll discuss types in more detail later on in the Type basics chapter, but for now it's useful to think in terms of plugs and connectors. For example, many of the plugs on the back of your computer are designed to have different shapes and sizes for a purpose. This is partly so that you don't inadvertently plug the wrong bits of your computer in together and blow something up. Types serve a similar purpose, but in this particular example, well, types aren't so helpful.
The quick solution to this problem is to specify a type for the number 25. For lack of other information, Haskell has "guessed" that 25 must be an
Haskell could in theory assign such polymorphic types systematically, instead of defaulting to some potentially incorrect guess, like Integer. But in the real world, this could lead to values being needlessly duplicated or recomputed. To avoid this potential trap, the designers of the Haskell language opted for a more prudent "monomorphism restriction". It means
that values may only have a polymorphic type if it can be inferred from the context, or if you explicitly give it one. Otherwise, the compiler is forced to choose a default monomorphic (i.e. non-polymorphic) type. This feature is somewhat controversial. It can even be disabled with the GHC flag (-fno-monomorphism-restriction), but it comes with some risk for inefficiency. Besides, in most cases, it is just as easy to specify the type explicitly.
the context from wikibooks
Following the previous example, you might be tempted to try storing a value for that radius. Let's see what happens:
Prelude> let r = 25
Prelude> 2 * pi * r
<interactive>:1:9:
Couldn't match `Double' against `Integer'
Expected type: Double
Inferred type: Integer
In the second argument of `(*)', namely `r'
In the definition of `it': it = (2 * pi) * r
Whoops! You've just run into a programming concept known as types. Types are a feature of many programming languages which are designed to catch some of your programming errors early on so that you find out about them before it's too late. We'll discuss types in more detail later on in the Type basics chapter, but for now it's useful to think in terms of plugs and connectors. For example, many of the plugs on the back of your computer are designed to have different shapes and sizes for a purpose. This is partly so that you don't inadvertently plug the wrong bits of your computer in together and blow something up. Types serve a similar purpose, but in this particular example, well, types aren't so helpful.
the new monomorphism-based explanation
The quick solution to this problem is to specify a type for the number 25. For lack of other information, Haskell has "guessed" that 25 must be an
Integer (which cannot be multiplied with a Double). To work around this, we simply insist that it is to be treated as a DoublePrelude> let r = 25 :: Double
Prelude> 2 * pi * r
157.07963267948966
Note
There is actually a little bit more subtlety behind this problem. It involves a language feature known as the monomorphism restriction. You don't actually need to know about this for now, so you can skip over this note if you just want to keep a brisk pace. Instead of specifying the typeDouble, you also have given it a polymorphic type, like Num a => a, which means "any type a which belongs in the class Num". The corresponding code looks like this and works just as seamlessly as before:Prelude> let r = 25 :: Num a => a
Prelude> 2 * pi * r
157.07963267948966
Haskell could in theory assign such polymorphic types systematically, instead of defaulting to some potentially incorrect guess, like Integer. But in the real world, this could lead to values being needlessly duplicated or recomputed. To avoid this potential trap, the designers of the Haskell language opted for a more prudent "monomorphism restriction". It means
that values may only have a polymorphic type if it can be inferred from the context, or if you explicitly give it one. Otherwise, the compiler is forced to choose a default monomorphic (i.e. non-polymorphic) type. This feature is somewhat controversial. It can even be disabled with the GHC flag (-fno-monomorphism-restriction), but it comes with some risk for inefficiency. Besides, in most cases, it is just as easy to specify the type explicitly.
2007-07-17
Write Yourself a Scheme in 48 Hours (PDF)
One of the wikibookians has made a rather nice PDF out of Johnathan Tang's Write Yourself a Scheme in 48 Hours. The conversion was done semi-automatically from mediawiki syntax to LaTeX [in Java... tsk]. Many thanks to Hagindaz for the conversion!
2007-07-15
monomorphism and the unintentional fib
The monomorphism restriction is a simple problem with a scary name.
I think I've run into the first instance where I have actually been able to identify something as being the monomorphism restriction in action (*). The good news is that if you don't understand what the restriction is, this might be your chance. The bad news is that many Haskell newbies might have been hurt in the process, because it involves an unintentional fib that I told in near the beginning of the Haskell wikibook.
(*) I'd appreciate it if somebody could fact-check me on this.
Oops! At this point, the reader runs into types for the very first time. This morning, I realised to my horror that I might have given a very wrong explanation of the problem to the gentle Haskell newbie. I said
Which is true, but is only sort of a half-truth. The problem with my explanation is that it lets the reader walk away with the mistaken belief that numbers without a decimal point, such as 25, can only be integers, when really they can be any
A concrete example of why it's important to get this right can be found further down the chapter. Here, I want to show that we can use variables within other variables. So here's what I have the reader type in
And here everything works... except...
Except if you are a sharp-eyed reader, you remember from above that I had just said that types prevent you from multiplying integers with reals and I had unintentionally implied that numbers like
I'm not entirely satisfied with this attempt (sorry), and want to deal with the situation more gracefully. Just don't know how to go about it yet.
Oh a word about the scary name 'monomorphism restriction'. I find it curious that I should have found that name scary for so long. I mean, for the longest time, I've told myself that I liked 'polymorphism' right? So how difficult would it have been to do a little etymology and notice that 'monomorphism' sounds exactly like 'polymorphism', except that you replace the 'poly-' (many) by 'mono-' (one). By the right, the two words have equivalent scariness! But for some reason, my brain somehow refused to recognise the fact. Instead, it associated one word with warm fuzzies and the other word with huh-does-not-compute.
Otherwise, one thing I found interesting about this is how you can simultaneously (a) hold a piece of knowledge and (b) not apply it consistently. For example, when I had written that module, I knew that numbers could be any
I think I've run into the first instance where I have actually been able to identify something as being the monomorphism restriction in action (*). The good news is that if you don't understand what the restriction is, this might be your chance. The bad news is that many Haskell newbies might have been hurt in the process, because it involves an unintentional fib that I told in near the beginning of the Haskell wikibook.
(*) I'd appreciate it if somebody could fact-check me on this.
circles and half-truths
High school Geometry. We've got a circle of radius 25 and we want to know its circumference (2 * pi * r). Now let's see what happens when we type it into GHCi
Prelude> let r = 25
Prelude> 2 * pi * r
<interactive>:1:4:
No instance for (Floating Integer)
arising from use of `pi' at:1:4-5
Possible fix: add an instance declaration for (Floating Integer)
In the second argument of `(*)', namely `pi'
In the first argument of `(*)', namely `2 * pi'
In the expression: (2 * pi) * r
Oops! At this point, the reader runs into types for the very first time. This morning, I realised to my horror that I might have given a very wrong explanation of the problem to the gentle Haskell newbie. I said
The main problem is that Haskell doesn't let you multiply Integers with real numbers. We'll explain why later, but for now, you can get around the issue by using a Double for r so that the pieces fit together:Prelude> let r = 25.0
Prelude> 2 * pi * r
157.07963267948966
Which is true, but is only sort of a half-truth. The problem with my explanation is that it lets the reader walk away with the mistaken belief that numbers without a decimal point, such as 25, can only be integers, when really they can be any
Num a. It's as if somebody had taught OCaml too recently and forgotten that haskell /= ocaml! (Coughs discretely)A concrete example of why it's important to get this right can be found further down the chapter. Here, I want to show that we can use variables within other variables. So here's what I have the reader type in
area = pi * 5^2:Prelude> let area = pi * 5^2
And here everything works... except...
Except if you are a sharp-eyed reader, you remember from above that I had just said that types prevent you from multiplying integers with reals and I had unintentionally implied that numbers like
5 are integers. So if you are a sharp-eyed reader, you look at that thing and you say to yourself, "HUH? That shouldn't work! You can't multiply an integer with a real!"monomorphism, like polymorphism without the poly
The real problem is not that we had setr to an integer. By right r = 25 should give us any Num a => a; however, since we do not give it a type signature, r gets restricted to being an Integer. In fact, the example of 2 * pi * r would have worked if (a) we had given r a polymorphic type signature or (b) we had run GHC with its 'no monomorphism restriction' extension.polymorphic type signature
Here we add an explicit type signature tor. Everything works:Prelude> let r :: Num a => a; r = 25(Thanks to shachaf on #haskell for reminding me that we can use
Prelude> 2 * pi * r
157.07963267948966
{}/; syntax and showing me how to apply it to write type signatures)-fno-monomorphism-restriction
And if you don't like type signatures, here's what it looks like running without the monomorphism restriction:dewdrop /tmp % ghci -fno-monomorphism-restrictionNo surprises.
___ ___ _
/ _ \ /\ /\/ __(_)
/ /_\// /_/ / / | | GHC Interactive, version 6.6, for Haskell 98.
/ /_\\/ __ / /___| | http://www.haskell.org/ghc/
\____/\/ /_/\____/|_| Type :? for help.
Loading package base ... linking ... done.
Prelude> let r = 25
Prelude> 2 * pi * r
157.07963267948966
helping the newbies
Clearly, my explanation needs to be fixed. I just need to figure out the right way to do it though. I really don't want to get too technical (the reader doesn't even know about types yet!), but I'll need to avoid lying to the reader. It's already bitten two users, and it took me one of my readers typing in this text for me to figure out what had happened:You might be thinking that this won't work--isn't 5 an integer, and therefore 5^2 also an integer? And didn't we just get an error trying to multiply pi by an integer?. What's going on is that when you "let r = 25", the "r" you get is more restricted than using the literal string "25" or 5^2. Try :t r and :t 5^2 and see the difference
I'm not entirely satisfied with this attempt (sorry), and want to deal with the situation more gracefully. Just don't know how to go about it yet.
knowing, Knowing and poly/mono
Oh a word about the scary name 'monomorphism restriction'. I find it curious that I should have found that name scary for so long. I mean, for the longest time, I've told myself that I liked 'polymorphism' right? So how difficult would it have been to do a little etymology and notice that 'monomorphism' sounds exactly like 'polymorphism', except that you replace the 'poly-' (many) by 'mono-' (one). By the right, the two words have equivalent scariness! But for some reason, my brain somehow refused to recognise the fact. Instead, it associated one word with warm fuzzies and the other word with huh-does-not-compute.
Otherwise, one thing I found interesting about this is how you can simultaneously (a) hold a piece of knowledge and (b) not apply it consistently. For example, when I had written that module, I knew that numbers could be any
Num a (and that you could do fun things making up crazy implementations of Num), yet at the same time as I was using this knowledge (I told myself 'true, but let's not talk about that now, no point confusing the newbies'), I can completely failed to apply that knowledge, because I went back and reflexively treated 25 as an Integer, probably due to all that freshman OCaml teaching. You know something, but you don't Know it.
2007-07-13
what's in season?
Another programming project for those of you who are just itching for something to code. Basically, I want a website which can tell me, given my current location, what fruits and vegetables are in season right now.
Some thoughts, questions and requirements
This project might also be a good way to learn about building user interfaces. Or maybe if you're not interested in working on that stuff, it would be a good opportunity to partner up with somebody else. They worry about the UI stuff and you worry about the code. I don't know anything about UI, except that I think it's important to get it right. If it helps, I greatly enjoyed Donald Norman's The Design of Everyday Things, as well as Bret Victor's Magic Ink.
Some thoughts, questions and requirements
- The site must be dead simple to and very pleasant to use. This is not something you should have to read documentation to figure out.
- This kind of thing could be easily international, so I want pictures. Maybe you can grab them from the Wikimedia Commons. I guess it would be fair to give you bonus points if you localise the thing, or maybe let me play with the language settings so I learn how to say 'rutabaga' in Arabic.
- How does the user tell you where s/he lives? As a default, it would be nice if you auto-detected it, but what might be nicer also is if I could play around and plug in different locations. How would you pick a location? By pointing at a map of the world? Also, maybe you don't just want a single point in the map, but a region of N kilometers around me. The question is basically, what grows N kilometers from where I live, where I get to specify
- Likewise, what do you do about the current date? It would also be nice if I can play around with this, asking not just 'what's in season right now' but 'what's in season during wintertime?'
- Where is all of your data coming from? How are you going to store it and look it up? What kind of data do you really need?
- If you want to get really really fancy, you can make the site adapt to current events. Maybe parse newspaper texts to find out that it's really not a good year for mangoes.
This project might also be a good way to learn about building user interfaces. Or maybe if you're not interested in working on that stuff, it would be a good opportunity to partner up with somebody else. They worry about the UI stuff and you worry about the code. I don't know anything about UI, except that I think it's important to get it right. If it helps, I greatly enjoyed Donald Norman's The Design of Everyday Things, as well as Bret Victor's Magic Ink.
2007-07-05
mediawiki code projects
Three more projects to practice your Haskell with, and produce something useful while you're at it:
(#3 might be a bit of work... and also, it's not clear that this is exactly what we want for converting wikibooks. It seems that the point would not be to expand the templates, but to convert them to something else. If I have a template called HaskellExercises, I don't want to expand it to a bunch of div tags or whatever; I want to convert it to something else)
- a mediawiki writer for Pandoc (should be a piece of cake)
- a mediawiki reader for Pandoc (perhaps less easy, note that there is also some HTML to deal with)
- a mediawiki template engine : given a set of mediawiki pages on the local filesystem, convert mediawiki input into mediawiki output, with all templates interpreted
(#3 might be a bit of work... and also, it's not clear that this is exactly what we want for converting wikibooks. It seems that the point would not be to expand the templates, but to convert them to something else. If I have a template called HaskellExercises, I don't want to expand it to a bunch of div tags or whatever; I want to convert it to something else)
2007-07-01
haskell for reprap?
Another potentially fun and probably big project for Haskellers: software for the RepRap project. The goal of RepRap is to build an open-source 3D printer for under $500 and with the ability to print out its own parts. Their control software is written in Java... borriiing.
Maybe this is the kind of niche that Haskell could jump in to, something a little unusual (like darcs and xmonad), and very useful at the same time (like darcs and xmonad). My rough thought was that we could similar successes with xmonad, building solid and minimal code for something that is real world (you don't get any more real than physical objects).
Maybe this is the kind of niche that Haskell could jump in to, something a little unusual (like darcs and xmonad), and very useful at the same time (like darcs and xmonad). My rough thought was that we could similar successes with xmonad, building solid and minimal code for something that is real world (you don't get any more real than physical objects).
2007-06-16
#haskell-books channel
Created on apfelmus's suggestion. Should provide a place for writers of Haskell books, tutorials, blogs, teaching materials of all sorts. We mostly had the wikibook in mind, but figured that others might like to join in on the fun. Real World?
Maybe we should host an annual monad tutorial contest or something, each year judging on different criteria, like "most creative use of tuna fish".
Maybe we should host an annual monad tutorial contest or something, each year judging on different criteria, like "most creative use of tuna fish".
2007-05-28
good, simple advice
I was looking at Audrey Tang's presentation Visual Basic rocks, and came across a piece of good, simple advice:
Dogmatic
✗
Humble
✔
Well put. I was grateful to get a little reminder, a little booster shot. I'm just hoping that I have taken it sufficiently to heart.
(I'm assuming you see the red X under 'Dogmatic' and the green check mark under 'Humble').
Dogmatic
✗
Humble
✔
Well put. I was grateful to get a little reminder, a little booster shot. I'm just hoping that I have taken it sufficiently to heart.
(I'm assuming you see the red X under 'Dogmatic' and the green check mark under 'Humble').
2007-05-21
burn your gas factories down
I've been Haskelling for three years now and have been loving it. The only discomfort is that from time to time I become painfully aware of my habit of making things horrible and ugly. Consider this code for instance:
List of random indices. It is a list [ rM, r(M+1), ..., rN ] where rX is a random number from X to N
This code has been called "clever". Anytime somebody calls your code "clever", you should begin to worry. I mean just look at that thing! You can positively hear the gears turning and the doodads clicking. This code is what the French call a "gas factory", something incomprehensibly and needlessly complex.
Stop micromanaging! Just tell the computer what you want, not what you want it to do
No gears or doodads. Geez... I don't what it is with me and making things more complicated than they need to be.
usine à gaz
List of random indices. It is a list [ rM, r(M+1), ..., rN ] where rX is a random number from X to N
> nexts g (l,h) = unfoldr nxt (g,l,h)
> where
> nxt (_,l,h) | l >= h = Nothing
> nxt (g,l,h) = let (r,g2) = randomR (l,h) g
> glh2 = (g2, l + 1, h)
> in Just (r, glh2)
This code has been called "clever". Anytime somebody calls your code "clever", you should begin to worry. I mean just look at that thing! You can positively hear the gears turning and the doodads clicking. This code is what the French call a "gas factory", something incomprehensibly and needlessly complex.
is there no simpler way?
Stop micromanaging! Just tell the computer what you want, not what you want it to do
> nexts2 g (l,h) = map (\x -> fst $ randomR (x,h) g) [l..h-1]
No gears or doodads. Geez... I don't what it is with me and making things more complicated than they need to be.
2007-05-20
unsort bis
Boy, do I feel like a big dummy!
Here is a super short and functional version I saw from a Pythonista on reddit.
Here is a super short and functional version I saw from a Pythonista on reddit.
import Data.List ( sort )
import System.Random ( Random, RandomGen, randoms, getStdGen )
main :: IO ()
main =
do gen <- getStdGen
interact $ unlines . unsort gen . lines
unsort :: (Ord x, RandomGen g) => g -> [x] -> [x]
unsort g es = [ y | (_,y) <- sort $ zip rs es ]
where rs = randoms g :: [Integer]
edit!
Heffalump points out that (i) if you have duplicates inrs, you don't get scrambling for the relevant bits (ii) this requires Ord x, which it really ought not to (although that is ani improvement from the array thing where I had to lock the type down for some reason)edit deux
Hmm... what does it mean to get a list of random arbitrary precision integers?unsort
Here's a small script I wrote partly for wikibook stuff and partly to learn how to use arrays and random numbers in Haskell.
I'm not a particularly enlightened Haskeller, so you might want to be careful about learning from me. Go ask somebody more experienced.
Note: one thing I'm a bit annoyed about is that I can't figure out how to make the unsort function generic, how to make it work for any type of array, element, index. Suggestions and by all means simplifications welcome.
given index at the next random index. Recursion to the next element until
we run out of indices.
I'm not a particularly enlightened Haskeller, so you might want to be careful about learning from me. Go ask somebody more experienced.
Note: one thing I'm a bit annoyed about is that I can't figure out how to make the unsort function generic, how to make it work for any type of array, element, index. Suggestions and by all means simplifications welcome.
unsort
> import Data.Ix ( Ix )Our objective is to scramble a list. To do this we convert the list into a mutable array and scramble it in place. This consists of traversing the array from left to right, swapping each element N with a random element from N to the end of the array.
> import Data.List ( unfoldr )
> import Data.Array.MArray ( MArray, getElems, newListArray, readArray, writeArray )
> import System.Random ( mkStdGen, getStdGen, Random, RandomGen, random, randomR )
> import Data.Array.IO
> main :: IO ()
> main =
> do gen <- getStdGen
> ins <- lines `fmap` getContents
> outs <- unsort gen ins
> putStr . unlines $ outs
The swapping itself is pretty straightforward. We swap the element at the
> unsort :: RandomGen g => g -> [String] -> IO [String]
> unsort g es =
> do arr <- newListArray (l,h) es :: IO (IOArray Int String)
> unsortH arr l idxs >>= getElems
> where
> idxs = nexts g (l,h)
> (l, h) = (1, length es)
given index at the next random index. Recursion to the next element until
we run out of indices.
And here is how we generate that list of random indices. It is a list [ rM, r(M+1), ..., rN ] where rX is a random number from X to N... Hmm... I'm pretty sure this can be greatly cut down
> unsortH :: (MArray a e m, Num i, Ix i) => a i e -> i -> [i] -> m (a i e)
> unsortH arr c [] = return arr
> unsortH arr c (r:rs) =
> do rElem <- readArray arr r
> cElem <- readArray arr c
> writeArray arr c rElem
> writeArray arr r cElem
> unsortH arr (c+1) rs
> nexts :: (RandomGen g, Num n, Ord n, Random n, Ix n) => g -> (n,n) -> [n]
> nexts g (l,h) = unfoldr nxt (g,l,h)
> where
> nxt (_,l,h) | l >= h = Nothing
> nxt (g,l,h) = let (r,g2) = randomR (l,h) g
> glh2 = (g2, l + 1, h)
> in Just (r, glh2)
2007-05-18
risk and recursion
Lately, I've been playing a bit of correspondence Risk with some childhood friends. The good thing about correspondence Risk, when you're scattered across twelve timezones is that it is inherently self-limiting. You are forced to wait your turn every day. Well, that was my hope anyway, but it turns out that things are not quite that simple. The problem is that though you may well your turn, nothing is stopping you in the meantime from thinking about World Domination instead of doing something useful.
But maybe something useful just came out of these daydreams. I was thinking that Risk might be a good tool for teaching programming techniques. For example, it seems calculating dice roll outcomes would a rather nice example for teaching recursion and dynamic programming. This is something we typically do with factorial and fibonacci, but for some students, that might get a little boring. Perhaps dice rolls aren't all that exciting either, but maybe you could sell the Risk angle an awaken your audience's inner ten year old. Maybe you could sell this as part of a bigger package... in this class, we'll be putting together our own Risk implementation, with fancy graphics and everything.
The idea is that you want to ask your program "if the attacker has 37 armies and the defender has 10, what is the most probable outcome and its probability (assuming that each side uses as many dice as possible)?"
My belief is that there is no way to calculate this 'instantly' and without computing all possibilities. You would have to basically crunch through each one of the (a * d) eventual outcomes. (anybody with halfway decent math skills want to confirm that?)
One idea you might able to show with this is just plain simple recursion (although you probably want to start with a simpler example first). So I've got 37 and 10, and if I need the expected outcomes of 37/8 (attacker wins), 36/9 (both win one), and 35/10 (defender wins), I could just factor in the probabilities of getting those.
But I thought was interesting was that you could show that there is some redundant computation going on here. You start at 37/10, but then you go into
which in turn expands into
Here, we are recalculating the scenarios 36/7, 35/8 and 34/9. What happens if we turn the crank some more? If I'm not mistaken, the naive algorithm would have to do 3^n calculations (loosely speaking), when really we shouldn't be doing any more than n^2.
I suppose what you'd really want is to have some kind of record of all the outcomes you've already computed. I'm not sure how it would work out code-wise or how you'd shift all those weights around (and if you are interested, I do invite you to cook up a quick implementation, RiskBuzz). I will observe, however, that this table could make it simple to turn around and ask a slightly more involved question, like "ok, so what are the three likeliest outcomes and their probabilities?"
But maybe something useful just came out of these daydreams. I was thinking that Risk might be a good tool for teaching programming techniques. For example, it seems calculating dice roll outcomes would a rather nice example for teaching recursion and dynamic programming. This is something we typically do with factorial and fibonacci, but for some students, that might get a little boring. Perhaps dice rolls aren't all that exciting either, but maybe you could sell the Risk angle an awaken your audience's inner ten year old. Maybe you could sell this as part of a bigger package... in this class, we'll be putting together our own Risk implementation, with fancy graphics and everything.
The idea is that you want to ask your program "if the attacker has 37 armies and the defender has 10, what is the most probable outcome and its probability (assuming that each side uses as many dice as possible)?"
My belief is that there is no way to calculate this 'instantly' and without computing all possibilities. You would have to basically crunch through each one of the (a * d) eventual outcomes. (anybody with halfway decent math skills want to confirm that?)
One idea you might able to show with this is just plain simple recursion (although you probably want to start with a simpler example first). So I've got 37 and 10, and if I need the expected outcomes of 37/8 (attacker wins), 36/9 (both win one), and 35/10 (defender wins), I could just factor in the probabilities of getting those.
But I thought was interesting was that you could show that there is some redundant computation going on here. You start at 37/10, but then you go into
| 37/10 | ||
| 37/8 | 36/9 | 35/10 |
which in turn expands into
| 37/10 | ||||||||
| 37/8 | 36/9 | 35/10 | ||||||
| 37/6 | 36/5 | 35/8 | 36/7 | 35/8 | 34/9 | 35/8 | 34/9 | 33/10 |
Here, we are recalculating the scenarios 36/7, 35/8 and 34/9. What happens if we turn the crank some more? If I'm not mistaken, the naive algorithm would have to do 3^n calculations (loosely speaking), when really we shouldn't be doing any more than n^2.
I suppose what you'd really want is to have some kind of record of all the outcomes you've already computed. I'm not sure how it would work out code-wise or how you'd shift all those weights around (and if you are interested, I do invite you to cook up a quick implementation, RiskBuzz). I will observe, however, that this table could make it simple to turn around and ask a slightly more involved question, like "ok, so what are the three likeliest outcomes and their probabilities?"
2007-05-06
iron coder
There ought to be something like Iron Chef for programming. Naturally, the Iron Coders would each represent a different paradigm: functional, imperative, object oriented, declarative. Actually, I have no idea how this would work and suspect it probably would not very entertaining at all. I just like the idea of summoning IRON CODER FUNCTIONAL! The guy rises with a platform and it's got a little lambda on it...
2007-05-01
haskell wikibook now featured
Spot the lambda?
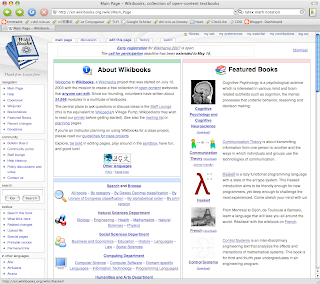
Haskell :: Functional Programming with Types is now a featured wikibook, which means that it will be rotated on to the front page on a regular basis.
There are around 40 books on the site that have this distinction, so if you don't see the Haskell book on the front page, try again in another hour or so.
Note that the wikibook version of Write Yourself a Scheme in 48 Hours has also been featured for quite some time. Yay, Johnathan! It's not on the front page yet, but should be making its way into the rotation at some point. Its blurb is
as follows:
Haskell :: Functional Programming with Types

Haskell :: Functional Programming with Types is now a featured wikibook, which means that it will be rotated on to the front page on a regular basis.
There are around 40 books on the site that have this distinction, so if you don't see the Haskell book on the front page, try again in another hour or so.
Write Yourself a Scheme in 48 Hours
Note that the wikibook version of Write Yourself a Scheme in 48 Hours has also been featured for quite some time. Yay, Johnathan! It's not on the front page yet, but should be making its way into the rotation at some point. Its blurb is
as follows:
| In this advanced Haskell tutorial, we will implement a significant subset of Scheme together. We assume no prior knowledge; however, we will be going fast. So if you're feeling ambitious, why don't you Write Yourself a Scheme in 48 Hours? |
2007-04-24
le gentle introduction
Je viens de voir sur Haskellwiki que la traduction du Gentle Introduction to Haskell est terminée. Félicitations et merci à Nicolas Vallée et TuTuX.
I just noticed that the French translation of A Gentle Introduction to Haskell has been complete. Thanks and congrats to the authors. Now how about a YAHT translation or a wikilivre on Haskell?
I just noticed that the French translation of A Gentle Introduction to Haskell has been complete. Thanks and congrats to the authors. Now how about a YAHT translation or a wikilivre on Haskell?
2007-04-20
Haskell wikibook blurb
The wikibooks project has a 'featured book' concept, in which the best books of the project are prominently displayed on the front page. The Haskell wikibook has been nominated to be listed as one of these featured books. Votes are positive so far, but nothing official yet. In the meantime, all wikibook authors are being encouraged to put together an advertising blurb for the front page.
Here is my attempt. Can you make it better? Please feel free to post ideas on this blog, or on the wikibook talk page.
(I'm not over-selling am I? I'm always worried about that)
Oh and the minimalist logo is just something I threw together (public domain, of course). Not married to it, just looking for something better than the current one.
Here is my attempt. Can you make it better? Please feel free to post ideas on this blog, or on the wikibook talk page.
| Haskell is a functional programming language with a state of the art type system. This book will introduce you to computer programming with our language of choice. It is friendly enough for new programmers, but deep enough to challenge the most experienced. Come stretch your mind with us! |
(I'm not over-selling am I? I'm always worried about that)
Oh and the minimalist logo is just something I threw together (public domain, of course). Not married to it, just looking for something better than the current one.
2007-04-19
pleac revamp - thanks!
Just wanted to say thanks to whoever it was that started the PLEAC revamp. Looks much more like Haskell now. The old notation-abuse version is now called haskell-on-steroids, which annoys me somewhat, but now we have less risk of confusing newbies. Will be interesting to see how they compare, the Haskell PLEAC and the wiki cookbook.
2007-04-13
congrats to hg!
I certainly do not speak for the darcs project as whole, but as a contributor and an enthusiastic fan. In any case, congratulations to the Mercurial team for adoption by Mozilla! I'm very happy to see Mercurial being adopted by both mutt and Mozilla, two projects that I also use. For me, it means that we're slowly starting to move on from centralised version control. There may be some pain involved, bugs to shake out and what not, but overall it's for the greater good. (That being said, I'm also pleased to see people upgrading from CVS to SVN, just climbing the ladder in general).
As for darcs, well, I hope that Jason's work will lead to the resolution of bug numero 1. No pressure, or anything. Just a little bit of progress, some useful new insights into the problem would be nice already.
Now if only I could work out all those Cabalisation issues...
As for darcs, well, I hope that Jason's work will lead to the resolution of bug numero 1. No pressure, or anything. Just a little bit of progress, some useful new insights into the problem would be nice already.
Now if only I could work out all those Cabalisation issues...
2007-03-31
instant dada
Just a small project idea for in case anybody is bored: write a small web toy that generates random blog entries in the style of a given blog.
My mental image would be basically to have a form in which the user can paste a URL. What the user should get back is a formatted blog post (maybe even using the right templates), and also html code that they can paste back into their own blogs.
You'll also want to figure out how to retrieve the individual blog posts, perhaps by using a feed-discovery mechanism. The result should be a single post with title, text and maybe even comments. Haskellers, especially newbies, might be particularly interested because it'll give you a chance with the Haskell XML stuff for parsing the RSS, PFP (for the text generation?) and HApps (for the web front-end). Many of the pieces are there. I remember seeing an RSS parser and a random text generator floating about, so it might just be a matter of cobbling things together.
If you're sucessful, you might even kick off one of those memes where people dada their own blogs as a post.
My mental image would be basically to have a form in which the user can paste a URL. What the user should get back is a formatted blog post (maybe even using the right templates), and also html code that they can paste back into their own blogs.
You'll also want to figure out how to retrieve the individual blog posts, perhaps by using a feed-discovery mechanism. The result should be a single post with title, text and maybe even comments. Haskellers, especially newbies, might be particularly interested because it'll give you a chance with the Haskell XML stuff for parsing the RSS, PFP (for the text generation?) and HApps (for the web front-end). Many of the pieces are there. I remember seeing an RSS parser and a random text generator floating about, so it might just be a matter of cobbling things together.
If you're sucessful, you might even kick off one of those memes where people dada their own blogs as a post.
2007-02-02
reading and writing UTF-8 in Haskell
We were discussing on the Haskell fr what it would take to work with UTF-8. Here is an example I cobbled together. Do whatever you want; it's going in the public domain. Note that I've also posted it to the wiki, so please make corrections there if you can.
Note that I don't really know what the best practices are wrt to reading and writing UTF-8, but here's what works for me.
We're going to be using the 2002 UTF-8 implementation by Sven Moritz Hallberg. I don't know if this is the best one, but it's what darcs uses. (I do wonder though, if it's worth turning it into a little library, something like Data.Char.UTF8)
We perform the demonstration on a list of files, specified as command line arguments. What we want to show is that we can both read and write UTF-8, so the demonstration will be of reading a file in, reverse every one of its lines, and writing it back out with the extension '.reversed'
For this to work, we need to have some helper functions for reading and writing [Word8]. I don't know if this is the right way to go about it.
Note that I don't really know what the best practices are wrt to reading and writing UTF-8, but here's what works for me.
> module Main where
> import Control.Monad (mapM_)
> import Data.Word (Word8)
> import Foreign.Marshal.Array (allocaArray, peekArray, pokeArray)
> import System.Environment (getArgs)
> import System.IO (hFileSize, Handle, hGetBuf, hPutBuf, openBinaryFile,
> IOMode(ReadMode, WriteMode))
We're going to be using the 2002 UTF-8 implementation by Sven Moritz Hallberg. I don't know if this is the best one, but it's what darcs uses. (I do wonder though, if it's worth turning it into a little library, something like Data.Char.UTF8)
> import UTF8
We perform the demonstration on a list of files, specified as command line arguments. What we want to show is that we can both read and write UTF-8, so the demonstration will be of reading a file in, reverse every one of its lines, and writing it back out with the extension '.reversed'
> main :: IO ()
> main =
> do args <- getArgs
> mapM_ reverseUTF8File args
> reverseUTF8File :: FilePath -> IO ()
> reverseUTF8File f =
> do fb <- readFileBytes f
> case decode fb of
> (cs, []) -> writeFileBytes (f ++ ".reverse") $ encode $ reverseLines cs
> (_, xs) -> fail $ show xs
> where
> reverseLines = unlines . map reverse . lines
For this to work, we need to have some helper functions for reading and writing [Word8]. I don't know if this is the right way to go about it.
> readFileBytes :: FilePath -> IO [Word8]
> readFileBytes f =
> do h <- openBinaryFile f ReadMode
> hsize <- fromIntegral `fmap` hFileSize h
> hGetBytes h hsize
>
> writeFileBytes :: FilePath -> [Word8] -> IO ()
> writeFileBytes f ws =
> do h <- openBinaryFile f WriteMode
> hPutBytes h (length ws) ws
> hGetBytes :: Handle -> Int -> IO [Word8]
> hGetBytes h c = allocaArray c $ \p ->
> do c' <- hGetBuf h p c
> peekArray c' p
>
> hPutBytes :: Handle -> Int -> [Word8] -> IO ()
> hPutBytes h c ws = allocaArray c $ \p ->
> do pokeArray p ws
> hPutBuf h p c
2007-01-31
think of a monad...
Think of a monad as a spacesuite full of nuclear waste in the ocean next to a container of apples. now, you can't put oranges in the space suite or the nucelar waste falls in the ocean, *but* the apples are carried around anyway, and you just take what you need. - Dons
Thought an illustration might be useful:
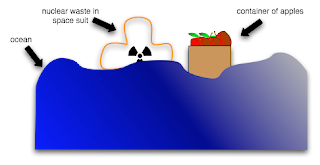
(Yes, yes, I know I have better things to be doing with my time)
Thought an illustration might be useful:

(Yes, yes, I know I have better things to be doing with my time)
2007-01-17
yaht latex now up to date with wiki
YAHT has two versions: a LaTeX one, which produces a nice PDF including margin notes, an index, etc; and a wiki(book) one, which provides an HTML view and instant editing.
The latex (darcs) version was lagging a bit behind the wiki one for a while, but it has now caught up. I'm quite pleased with the results. I have received 3 darcs patches so far, which may not be huge, but is still better than nothing. More importantly, I have observed that people still like going to the PDF version a lot, so we know that keeping that up to date is important. Having YAHT on the wiki has certainly been useful as well. In the two and half months since its wikification, you have not only corrected countless crappy-script-induced-deformations, over a dozen factual errors, and twice as many typos or spelling/grammatical errors. Good work, Haskellers!
Note also that keeping the LaTeX version up to date should now be a lot easier, thanks to (1) a cleaned up and less noisy conversion script (2) stupid darcs tricks. I've got three branches: the (noisy) auto-convered version (latex-to-darcs), a "production" version, which has less noise than the prior, and an MVS version, which pulls in changes from the wiki. The noisy version has some gunk from my scripts that I just have to revert. The MVS version has some changes which only affect noise (errors in where I put my
The latex (darcs) version was lagging a bit behind the wiki one for a while, but it has now caught up. I'm quite pleased with the results. I have received 3 darcs patches so far, which may not be huge, but is still better than nothing. More importantly, I have observed that people still like going to the PDF version a lot, so we know that keeping that up to date is important. Having YAHT on the wiki has certainly been useful as well. In the two and half months since its wikification, you have not only corrected countless crappy-script-induced-deformations, over a dozen factual errors, and twice as many typos or spelling/grammatical errors. Good work, Haskellers!
Note also that keeping the LaTeX version up to date should now be a lot easier, thanks to (1) a cleaned up and less noisy conversion script (2) stupid darcs tricks. I've got three branches: the (noisy) auto-convered version (latex-to-darcs), a "production" version, which has less noise than the prior, and an MVS version, which pulls in changes from the wiki. The noisy version has some gunk from my scripts that I just have to revert. The MVS version has some changes which only affect noise (errors in where I put my
2007-01-16
House runs under Parallels
House is an operating system written in Haskell. Ever since CSE380 (titled "Operating Systems") and my many many segfaults, I have deeply impressed with those I call "people who know how computers work". So whenever somebody says "I wrote an operating system!"... I simply marvel.
Anyway, was just sort of fiddling with my computer trying to see if I can get it to run, but I was having the toughest time! The thing boots fine under Q (the qemu front end), but nothing I did could make it work on Parallels. Tried renaming it with .hdd extension, but then I just got a grub prompt with no idea how to proceed. Renaming it to .fdd and connecting it as a floppy wouldn't work, so my first reaction was "oh! it must be some kind of crazy Parallels-specific format", so I kept searching the web and asking on IRC, trying to see if anyone know how to produce Parallels-compatible bootable floppy images...
Well you know what the problem was?
Next to the floppy drive icon [connected to hOp-0.8.fdd] are two checkboxes, Enabled and Connect on Startup. Connect on Startup was unchecked.
Yes eric, you have to put the disk in the drive for it to work... good job!
What a dolt.
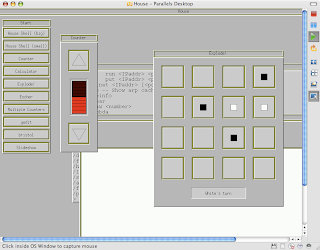
And the second is of the whole desktop (probably a little gratuitous):
If you're having trouble getting this to work on your machine:
Parallels might crash the first two times you do this. I have no idea why, but it seems to work after that.
Anyway, was just sort of fiddling with my computer trying to see if I can get it to run, but I was having the toughest time! The thing boots fine under Q (the qemu front end), but nothing I did could make it work on Parallels. Tried renaming it with .hdd extension, but then I just got a grub prompt with no idea how to proceed. Renaming it to .fdd and connecting it as a floppy wouldn't work, so my first reaction was "oh! it must be some kind of crazy Parallels-specific format", so I kept searching the web and asking on IRC, trying to see if anyone know how to produce Parallels-compatible bootable floppy images...
Well you know what the problem was?
Next to the floppy drive icon [connected to hOp-0.8.fdd] are two checkboxes, Enabled and Connect on Startup. Connect on Startup was unchecked.
Yes eric, you have to put the disk in the drive for it to work... good job!
What a dolt.
Edit 2006-01-17
Here are a couple of screenshots, as requested. The first is just the Parallels window:
And the second is of the whole desktop (probably a little gratuitous):

If you're having trouble getting this to work on your machine:
- Rename hOp-0.8.flp to hOp-0.8.fdd
- Add it as the floppy disk drive to your virtual machine
- Set the boot sequence to start with the floppy (or at least, have the floppy somewhere)
- Remember to click that Connect on Setup button next to the floppy config
Parallels might crash the first two times you do this. I have no idea why, but it seems to work after that.
2007-01-07
nous sommes huit (#haskell.fr)
Le nombre d'utilisateurs sur #haskell.fr (irc.freenode.net) a encore doublé. On est 8, maintenant, 8 êtres humains. Je vais noter chaque passage à 2X jusqu'à 32. J'imagine que à partir de cette taille, le channel n'aura plus besoin d'encouragement.
Ick. Eric-French is scary. There's now 8 of us in #haskell.fr (or rather, 8 max) and that's bona fide human beings too. I'm going to note each of these doublings until there's 32 of us. At that point, I figure that we're not going to need anybody blowing on the fire.
Francophone Haskeller? Come on in! And stick around; just put it in your automated login. If #haskell is too busy for you, consider maybe #haskell.fr as a quieter alternative. We want newbies, experts and curious hangers-on alike. It would be especially good if experienced Haskellers hung around, because newbies really should not be taking advice from yellow-belt Eric. Oh, and unless they kick me out, non-native speakers bienvenues.
Ick. Eric-French is scary. There's now 8 of us in #haskell.fr (or rather, 8 max) and that's bona fide human beings too. I'm going to note each of these doublings until there's 32 of us. At that point, I figure that we're not going to need anybody blowing on the fire.
Francophone Haskeller? Come on in! And stick around; just put it in your automated login. If #haskell is too busy for you, consider maybe #haskell.fr as a quieter alternative. We want newbies, experts and curious hangers-on alike. It would be especially good if experienced Haskellers hung around, because newbies really should not be taking advice from yellow-belt Eric. Oh, and unless they kick me out, non-native speakers bienvenues.
2007-01-06
haskell wikibook print version
Just a quick note to mention that the wikibook's print edition is now automatically generated by a script. 90ish lines of what I hope to be reasonable-looking Haskell code. It should make it easier to keep that print version synched up.
Subscribe to:
Posts (Atom)
